How to Move Ahead of the Three Pillars of Observability
The acceleration in digitalization, also due to the pandemic, has brought an organization’s business and IT teams and strategic goals closer together than ever before.
Chief Information Officers (CIOs) have existed since the early 1980s and, until recently, their typical role was primarily focused on managing the technology infrastructure. But in a post-pandemic world, that role is now expanding beyond traditional IT responsibilities.
According to E&Y, 96% of CIOs confirmed that their role has expanded (from leading digital transformation) to also co-architecting business transformation.
Along those lines, full-stack observability has evolved into being both a business and IT tool. A business perspective on full-stack observability has become critical for technologists to appraise IT performance insights with real-time business data.
What is Observability?
Simply put, observability means inferring the internal state of a system from its external outputs.
Observability is essential in helping improve application performance and resilience, keeping systems running smoothly, as well as maintaining quality and reliable service to an organization’s users and customers.
It also helps technologists understand what happens externally to their tech stack: including events across the cloud and the internet.
But the value of observability doesn’t stop with these IT use case cases. It also lends an invaluable window into the business impact of your digital product or service. In turn, it helps prioritize business decisions, measure and improve your Customer Experience (CX), optimize conversion rates, and so much more.
Observability: The Current State
According to VMware, 16% of IT experts are already using observability tools and another 35% are planning to implement them within the next 12 months.
But 96% are reporting problems with their current approach.
So, what’s the disconnect?
Although observability outperforms traditional tools in keeping up with new technological trends (hybrid infrastructure, microservices, edge computing, etc.), it also comes with its fair share of challenges.
For example, organizations are facing an unprecedented wave of operational and security observability data. This data is complex, multidimensional, and high velocity. And without a single source of truth for data, it is difficult for teams to zero in on performance issues across the stack.
Plus, organizations that still rely (whether partly or largely) on legacy systems struggle to even get started with observability. Long release cycles and largely unstandardized protocols for edge cases do not help either.
Also, even with load testing in pre-production, it remains impossible for developers to predict how real users will impact applications and infrastructure before they push the code into production.
And after all, users have more expectations than ever before. According to Forrester and when it comes to CX, companies will have to “make the grand pivot from reactionary to revolutionary,” which should see many of them designing long-term solutions that right-size their CX projects and investments.
But most immediately, with the dynamic pace of change and advances in the world of technology, it might also be time for us to revisit our approach to observability – philosophically.
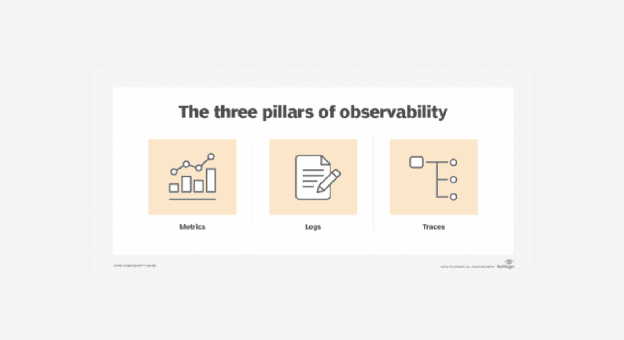
The Outdated Approach to Observability: The Three Pillars of Observability
Today, observability is defined as a collection of data types. Telemetry data enables us to infer the health status of an application, and the amount and variety of it influence the ultimate observability level. More specifically, this is done through the three pillars of observability:
Pillar 1: Logs
Messages that are produced during the component execution and capture relevant information.
Pillar 2: Metrics
Visibility into good and bad events that happen inside of an application.
Pillar 3: Distributed traces
Records of the data flow between different components and execution details.
The shortfall? Defining observability through inputs prioritizes technical instrumentation and underlying data formats over the outcome.
After all, the generation of the three data types does not guarantee pattern recognition, conclusions, or specific outcomes. Plus, many organizations struggle to find the correlation between the sheer amount of data output versus the value derived from it.
Observability Revamped: The Three Phases of Observability
Thus, while logs, metrics, and distributed traces are all critical inputs to observability, they are not observability solutions in and of themselves.
The alternative many organizations are turning to? An approach focused on outcomes rather than inputs: the three phases of observability.
Phase 1: Know
Or: how quickly do I know that there is a problem?
The key is to shrink the time between an issue arising and an alert firing. And the fastest and most effective path to recognizing a problem is an actionable notification with correlated metrics, traces, and potentially even logs – directed to the right team.
Phase 2: Triage
Or: how to stop the problem from creating additional damage?
Mapping the precise scope of an issue accelerates successful remediation. Contextualizing the issue for the engineers is key. E.g. which customers are impacted? How many are there? What systems are impacted and to which degree? This step is also key in determining and prioritizing remediation efforts across urgency levels.
Phase 3: Understand
Or: what is the root cause of the problem?
In this final stage, teams need to shift quickly to find out where and how the issue started. This approach is not only key to recognizing patterns (by linking alerts to recurring root causes), but also to prevent the same issues from happening again. Ideally over time, establishing probable causes in alert notifications will further reduce the time to root cause.
And the common focus during each phase is the alleviation of customer impact and problem remediation – in the fastest way possible.
Conclusion
There’s a good reason that observability is a top 3 project at the Native Computing Foundation (right after Kubernetes).
Simply, organizations that get better at building and maintaining software pull away from those that don’t. Great observability leads to a competitive advantage, rapid innovation, and happier engineers and customers.
And as companies move to modern observability platforms, they start to see the benefits in performance and availability. These benefits further accelerate as companies move along the maturity curve. One of the ways in exactly that is prioritizing outcomes over data and inputs.